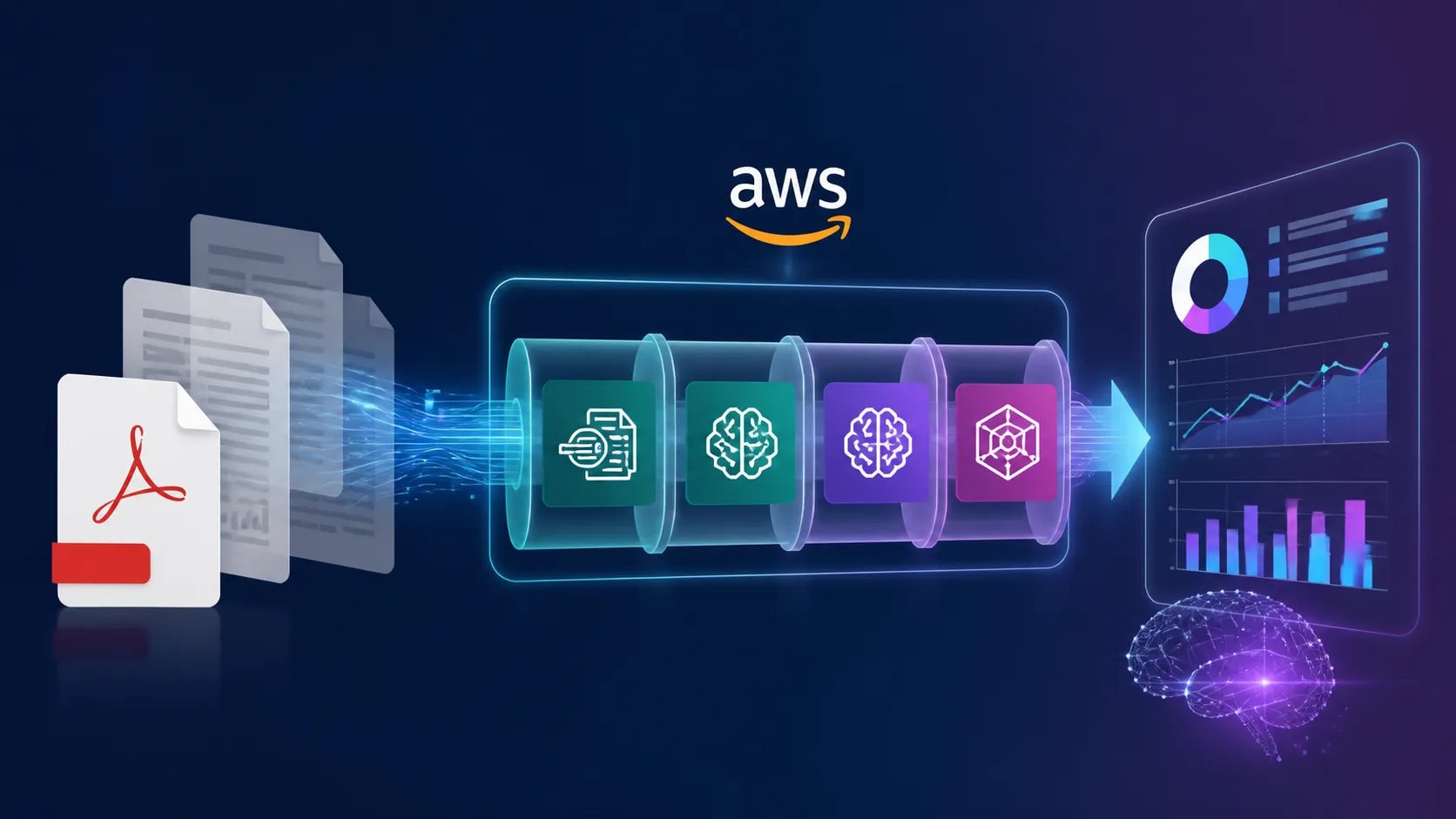
April 16, 2025, (Inside AI) — Amazon Web Services has unveiled a blueprint for an intelligent document processing pipeline that leans heavily on its generative AI stack, promising to turn messy, unstructured files into structured, query-ready insights. The architecture stitches together Amazon Bedrock Data Automation, Step Functions, Bedrock Knowledge Bases, and agentic coordination to handle everything from property reports to financial charts at scale.
The core of the system is Bedrock Data Automation, a managed service that goes beyond simple optical character recognition. It classifies documents, extracts text in reading order, parses tables, and even interprets visual elements like charts and diagrams. The pipeline then indexes that output into a knowledge base for semantic search, while specialized agents handle tasks like market analysis or cross-document validation.
AWS claims the approach can slash processing time dramatically. In one example, a commercial real estate firm cut initial property screening from three to four hours down to 15 to 20 minutes per report. The system was tested on over 50,000 PDFs concurrently without performance degradation, the company said.
The Orchestration Under the Hood
Documents land in an S3 bucket, triggering a Step Functions workflow that records metadata in DynamoDB and fires off an asynchronous Bedrock Data Automation job. The service automatically splits multi-page files, classifies sections, and matches them to processing blueprints. A task token pattern lets the workflow wait efficiently for completion, handling errors like timeouts or unsupported formats without losing documents.
Bedrock Data Automation offers two output modes. Standard output provides summaries, extracted text, and figure captions. Custom blueprints let users define specific fields for document types like invoices or bank statements. One blueprint per document type keeps extraction consistent, while the service auto-matches each file to the right blueprint.
Visuals Get Their Own Pipeline
Charts and diagrams, often a blind spot for traditional OCR, receive special treatment. The service generates captions, extracts data points and trends, and returns bounding box coordinates. That structured data then flows into Bedrock Knowledge Bases, where it is indexed alongside text for retrieval-augmented generation queries.
Agents hosted on Bedrock AgentCore Runtime route requests to specialized workers: market analyst agents for financial reports, external API agents for real-time data, and coordinator agents that cross-check market data against historical knowledge bases. The result is a system that can answer questions like "Show me properties with projected IRR above 12% and debt coverage ratios over 1.25" by pulling from multiple documents and sources.
Cost and Security Levers
The design includes cost optimization strategies such as intelligent routing, where simple text documents use basic extraction while complex files get advanced processing. Batch processing combines multiple documents into single API requests, and S3 lifecycle policies move older files to cheaper storage tiers. On the security side, AWS KMS encrypts documents and results, PrivateLink keeps API access within VPC boundaries, and IAM roles enforce least-privilege access.
Deployment relies on AWS CDK for infrastructure as code, with four main stack components mirroring the architecture layers. The full implementation is available on GitHub, but it requires Bedrock Data Automation access in one of eight supported regions, including US East, US West, and several European and Asia Pacific locations.
What the Blueprint Leaves Out
While the post details a successful proof of concept, it sidesteps hard numbers on accuracy or error rates across document types. No independent benchmarks or third-party validation are cited, making it difficult to assess how the system performs on noisy, real-world scans versus clean digital files. The reliance on Bedrock's managed services also raises vendor lock-in concerns, as the pipeline is tightly coupled to AWS's proprietary AI stack.
Competing approaches from Google Cloud's Document AI or Microsoft's Azure AI Document Intelligence offer similar multimodal extraction, often with more transparent pricing and prebuilt models for common industries. AWS's advantage may lie in the tight integration with its broader ecosystem, but organizations evaluating this architecture will need to weigh the trade-offs between convenience and portability.
The post frames the solution as a strategic shift from cost center to business asset, yet it does not address the ongoing operational burden of maintaining custom blueprints as document types evolve. As with any AI pipeline, the initial build is only part of the story; continuous monitoring and retraining will determine long-term value.







